
与时俱进,诚赢客户
十年散热器、离心风机、压缩机制造厂家
全国服务热线400-123-4567
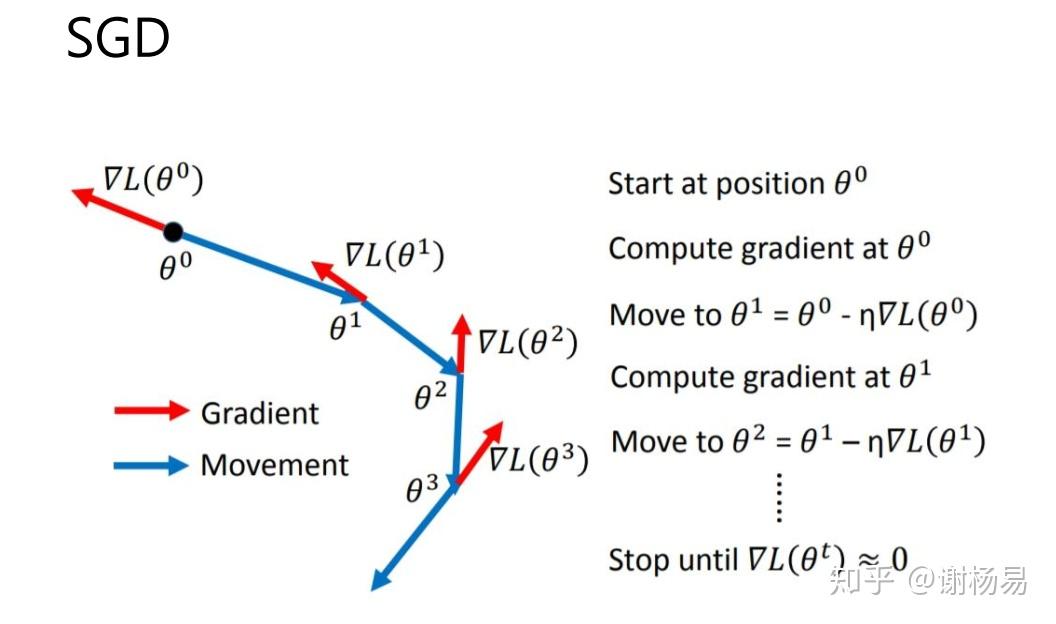
刚开始做一个新问题的时候,你会选择那种优化器(sgd,adam,或其他),lr 调节策略会选择什么(阶梯式 乘0.1,指数下降,warm up,cyclic?)。得到这个默认设置的过程中你趟过哪些坑
cv 里CNN基本上以momentum sgd为主;nlp 里transformer-based model以adam为主,好像还没统一?
SGD,因为我穷,只有一块垃圾GPU,所以希望算的快一点。
在数据制作环节中,提到minibatch思想用于数据批次量获取,是一种优化器思想,而该文则是对各种优化器进行介绍。
优化器:最小化损失函数算法,把深度学习当炼丹的话,优化器就是炉子,决定火候大小,炉子属性等,在深度学习监督学习的模型中,常用梯度下降法求解最优参数;
学习率:在优化器中,决定着梯度下降的速度,炉子调整火候的时间点;
Pytorch中,torch.optim 提供优化器类型选择,torch.optim.lr_scheduler 提供学习率调整策略;
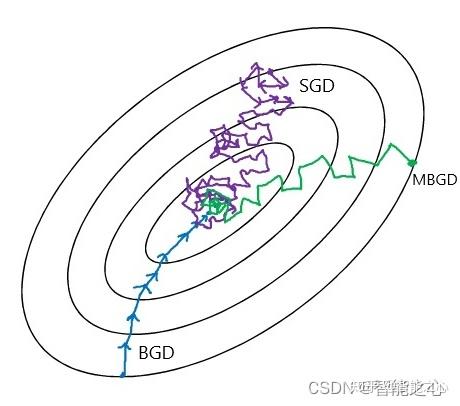
梯度下降方法(Gradient Descent)变体如图所示,BGD全样本训练,计算量太大,计算速度慢;SGD太过震荡,容易陷入鞍点找不到最优点;MBGD训练稳定,计算速度快;
SGD 公式 即使采用MBGD的方法仍然有很大难题,还不能保证良好的收敛性。
- 学习率选择和设计问题;
- 参数更新都在同一个学习率下更新的,实际训练特征出现频率少的需要更大的学习率;
由 SGD -> Momentum Momentum,动量法, 除了保留$?θJ(θ{t?1})$该位置的梯度向量,同时加入$v_{t?1}$考虑上一次梯度向量,保证更新的梯度方向不会过分偏离上一次梯度,从而方向抖动不会很明显,前进方向由惯性动量决定,因此,$γ$称为动量超参。可以看出,缺陷还是很明显的,所有参数还是无法逃离共享同一个学习率的命运。
由 Momentum -> Nesterov Accelerated Gradient Nesterov Accelerated Gradient,NAG加速动量法,当前位置梯度加入$-γv_{t?1}$近似预测未来的权重,部分RNN网络上表现良好,比Momentum震荡幅度会小,“冲坡”不至于太快 。
# NAG加速动量法
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3, momentum=0.9, nesterov=True)
Adagrad(Adaptive Gradient 自适学习率应梯度下降) 其中,$\\Delta θ_t$项是 $θ_t$ 的差值,更新较频繁的$θ_t$累计的$n_t$越大,分母越大,学习率变小,从而$θ_i$的学习率就调小。因此,$Adagrad$对于更新频率较低的参数用较大的学习率,对于更新频率较高的参数用较小的学习率。
有的时候学习速率收敛的过快会导致模型在训练到局部最优解前就停止参数更新。为了解决这个问题,人们提出了RMS Prop梯度下降法
Adadelta & Rmsprop 优点是不需要指定学习率
Adaptive Moment Estimation(Adam) 本质是带 Momentum 的 RMSProp 方法,新手推荐该方法,万金油。
# Adam
optimizer=torch.optim.SGD(model.parameters(), lr=1e-3, momentum=0.9, nesterov=True)
PyTorch提供的学习率调整策略分为三大类,分别是
- 有序调整:等间隔调整(Step),按需调整学习率(MultiStep),指数衰减调整(Exponential)和余弦退火(CosineAnnealing)。
- 自适应调整:自适应调整学习率 ReduceLROnPlateau。
- 自定义调整:自定义调整学习率 LambdaLR。
注:PyTorch提供的学习率调整策略, 学习率调整策略接在优化器后头即可,torch.optim.lr_scheduler为代码接口。
# 对构建的模型选择 optimizer :: torch.optim
optimizer=torch.optim.Adam(model.parameters(), lr=1e-3)
# 对optimizer选择 learning_rate :: torch.optim.lr_scheduler
scheduler=torch.optim.lr_scheduler.StepLR(optimizer, step_size=500, gamma=0.9)
各类 optimizer 的原理
自适应学习率优化器伪代码
优化器推导公式
优化器文字描述推荐
优化器方法
pythorch优化器学习率写法
md符号
【Pytorch 】笔记七:优化器源码解析和学习率调整策略
【Pytorch 】笔记六:初始化与18种损失函数的源码解析
kaggle学习率示例:https://www.kaggle.com/code/isbhargav/guide-to-pytorch-learning-rate-scheduling/notebook
选AdamW,lr会具体情况具体分析,一般有个预热,后面阶梯式或cosine
SGD全称Stochastic Gradient Descent,随机梯度下降,1847年提出。每次选择一个mini-batch,而不是全部样本,使用梯度下降来更新模型参数。它解决了随机小批量样本的问题,但仍然有自适应学习率、容易卡在梯度较小点等问题。
SGDM即为SGD with momentum,它加入了动量机制,1986年提出。
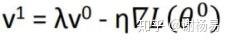
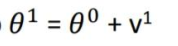
如上所示,当前动量V由上一次迭代动量,和当前梯度决定。第一次迭代时V0=0,由此可得到前三次迭代的动量
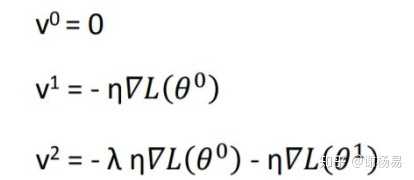
由此可见t迭代的动量,其实是前t-1迭代的梯度的加权和。λ为衰减权重,越远的迭代权重越小。从而我们可以发现,SGDM相比于SGD的差别就在于,参数更新时,不仅仅减去了当前迭代的梯度,还减去了前t-1迭代的梯度的加权和。由此可见,SGDM中,当前迭代的梯度,和之前迭代的累积梯度,都会影响参数更新。
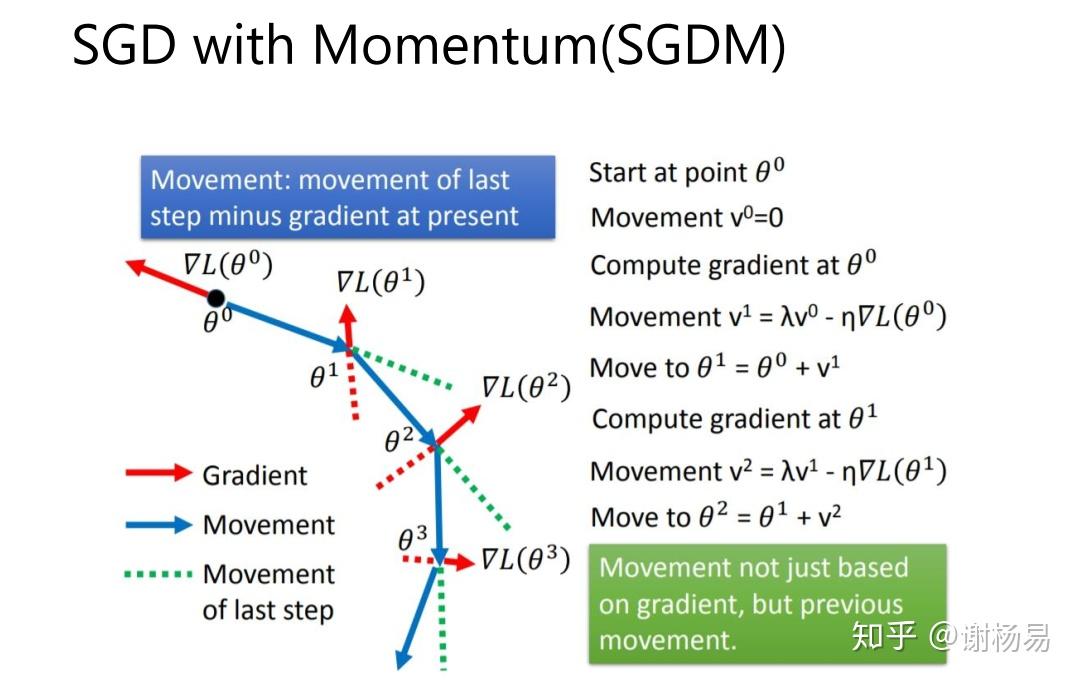
SGDM相比SGD优势明显,加入动量后,参数更新就可以保持之前更新趋势,而不会卡在当前梯度较小的点了。
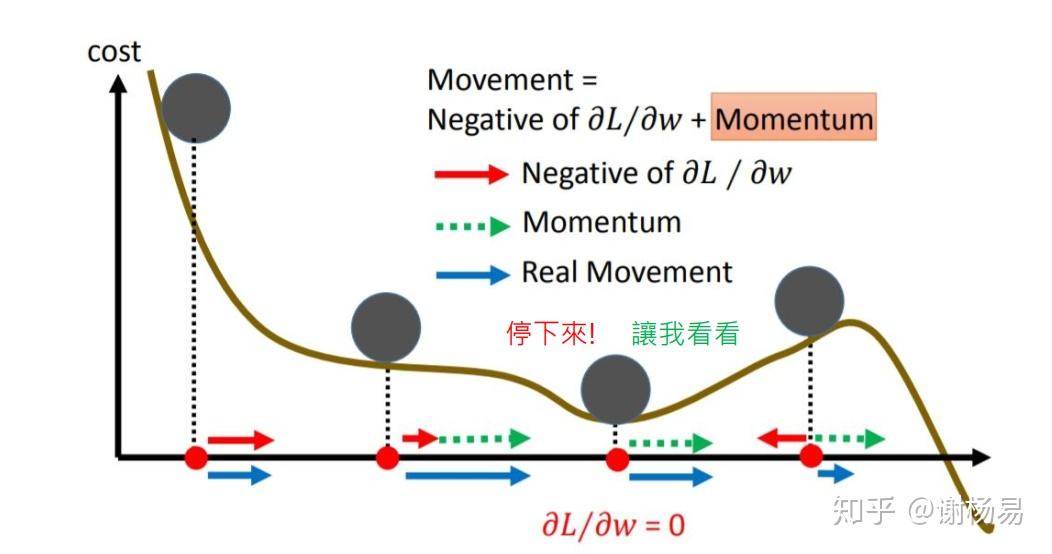
美中不足的是,SGDM没有考虑对学习率进行自适应更新,故学习率的选择很关键。
它利用迭代次数和累积梯度,对学习率进行自动衰减,2011年提出。从而使得刚开始迭代时,学习率较大,可以快速收敛。而后来则逐渐减小,精调参数,使得模型可以稳定找到最优点。其参数迭代公式如下
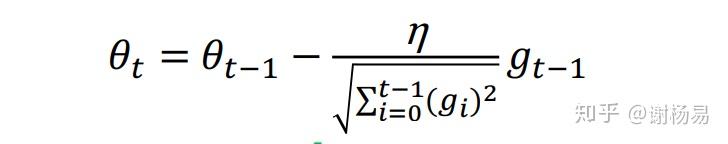
与SGD的区别在于,学习率除以 前t-1 迭代的梯度的平方和。故称为自适应梯度下降。
Adagrad有个致命问题,就是没有考虑迭代衰减。极端情况,如果刚开始的梯度特别大,而后面的比较小,则学习率基本不会变化了,也就谈不上自适应学习率了。这个问题在RMSProp中得到了修正
它与Adagrad基本类似,只是加入了迭代衰减,2013年提出,如下
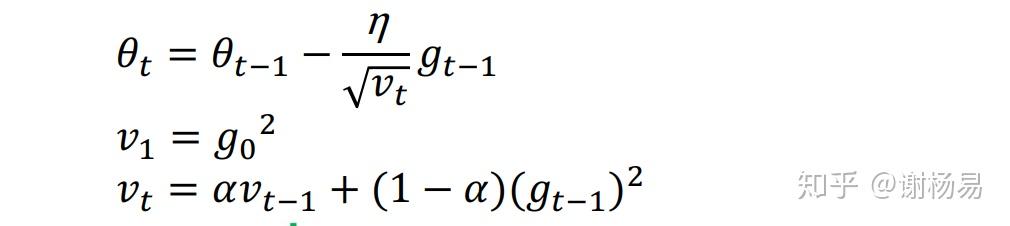
观察上式和Adagrad的区别,在于RMSProp中,梯度累积不是简单的前t-1次迭代梯度的平方和了,而是加入了衰减因子α。简单理解就是学习率除以前t-1次迭代的梯度的加权平方和。加入衰减时make sense的,因为与当前迭代越近的梯度,对当前影响应该越大。另外也完美解决了某些迭代梯度过大,导致自适应梯度无法变化的问题。
Adam是SGDM和RMSProp的结合,它基本解决了之前提到的梯度下降的一系列问题,比如随机小样本、自适应学习率、容易卡在梯度较小点等问题,2015年提出。如下

由上可见,mt即为动量,根号vt即为自适应学习率。加入了两个衰减系数β1和β2。刚开始所需动量比较大,后面模型基本稳定后,逐步减小对动量的依赖。自适应学习率同样也会随迭代次数逐渐衰减。 则是防止除数为0,仅仅是数学计算考虑。
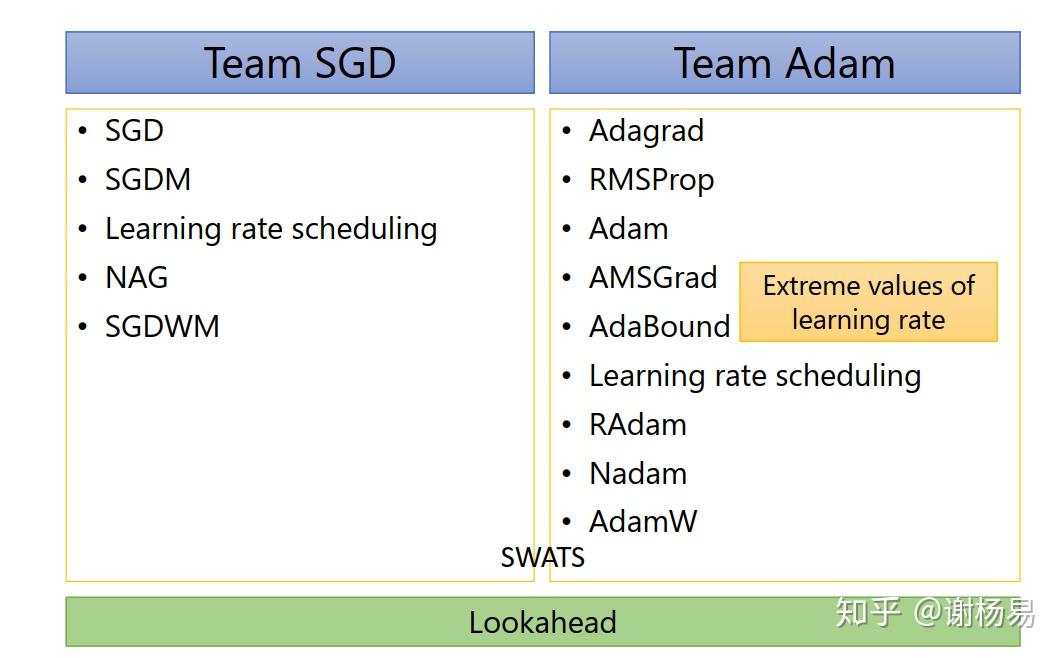
五大优化器其实分为两类,SGD、SGDM,和Adagrad、RMSProp、Adam。使用比较多的是SGDM和Adam。
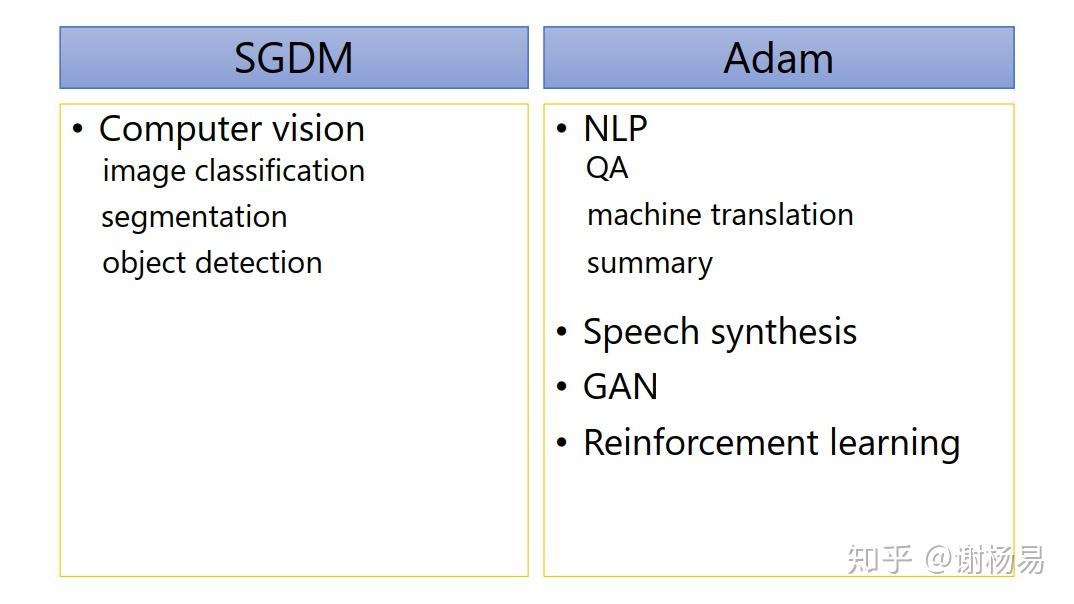
如上所示,SGDM在CV里面应用较多,而Adam则基本横扫NLP、RL、GAN、语音合成等领域。所以我们基本按照所属领域来使用就好了。比如NLP领域,Transformer、BERT这些经典模型均使用的Adam,及其变种AdamW。
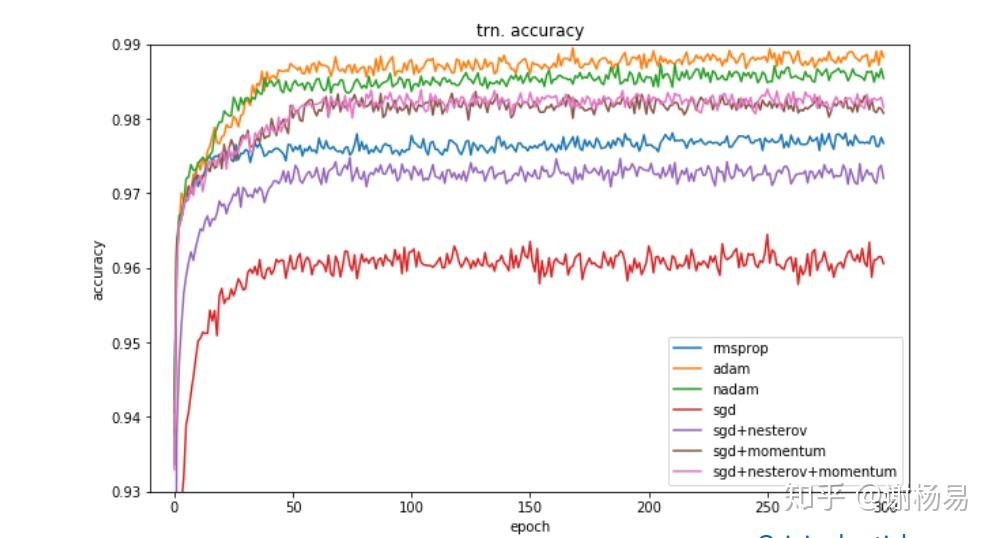
有人研究过几大优化器在一些经典任务上的表现。如下是在图像分类任务上,不同优化器的迭代次数和ACC间关系。
SGD > Adam Which One Is The Best Optimizer: Dogs-VS-Cats Toy Experiment
训练集上
验证集上
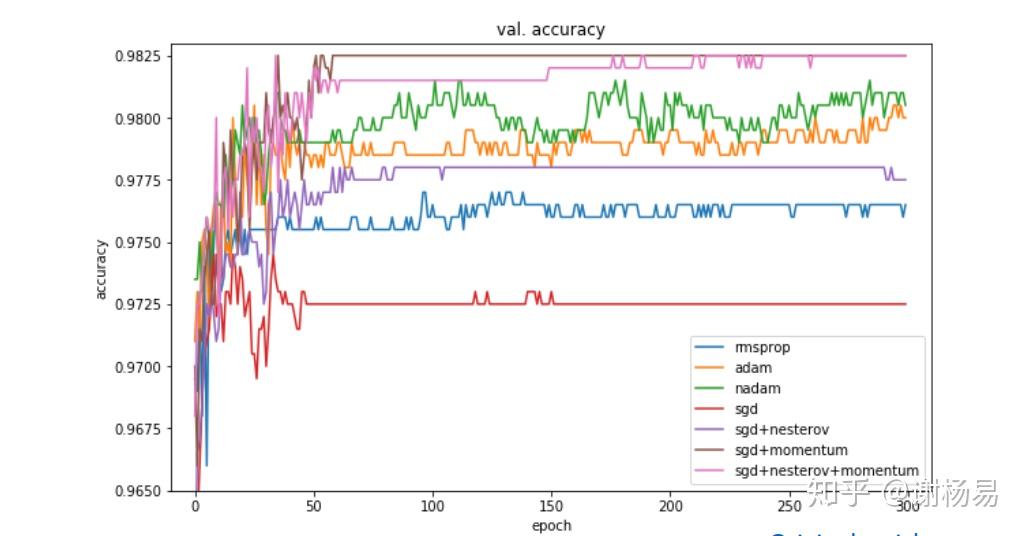
可见
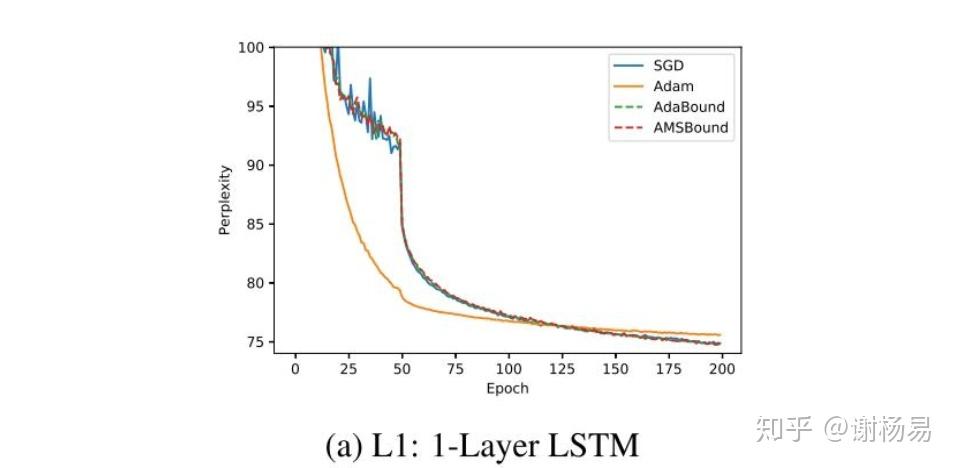
LSTM模型上,可见Adam比SGDM收敛快很多。最终结果SGDM稍好,但也差不多。

SGDM训练慢,但收敛性更好,训练也更稳定,训练和验证间的gap也较小。而Adam则正好相反。
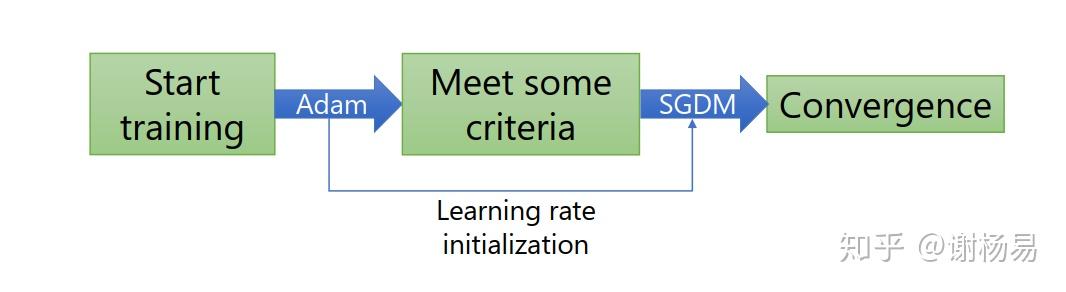
结合了SGDM和Adam,刚开始使用Adam,使得模型快速收敛。然后使用SGDM,使模型收敛稳定。如下
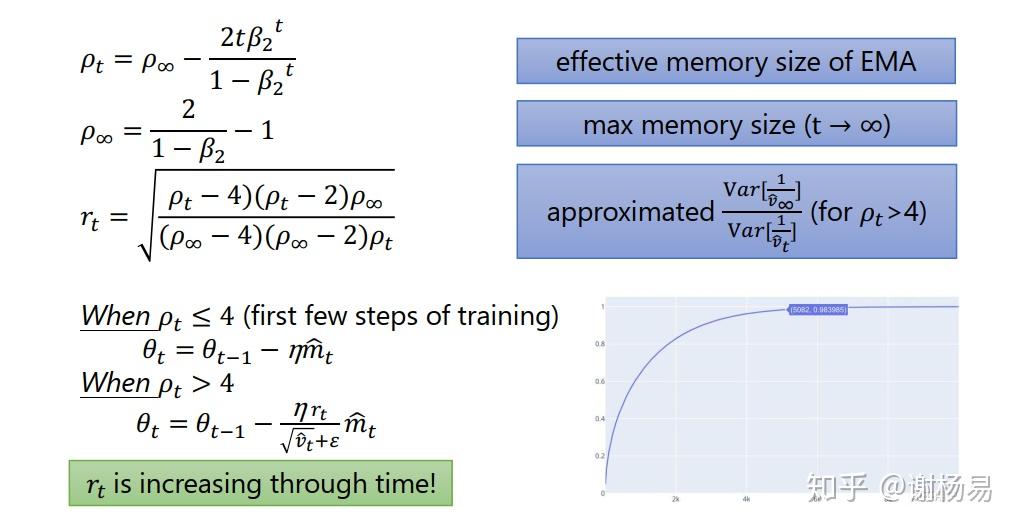
对Adam的改进在于,学习率衰减Vt变为了取max,如下。
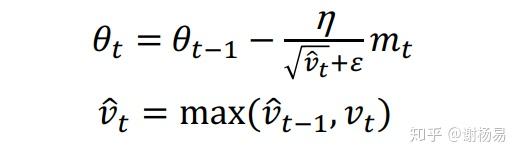
优点为
AMSGrad处理了较大的学习率,而AdaBound则将学习率限制在一定范围内
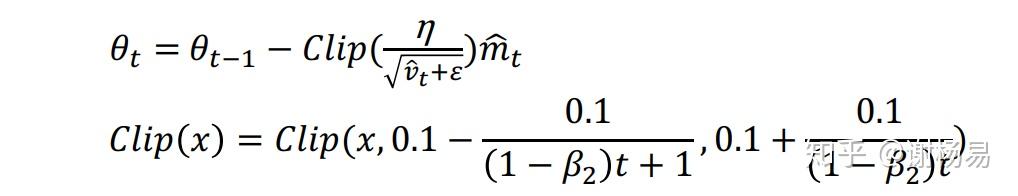
针对于SGDM收敛过慢,且没有使用自适应学习率的问题,Cyclical LR提出了让学习率在一定范围内变大和变小的方法,如下
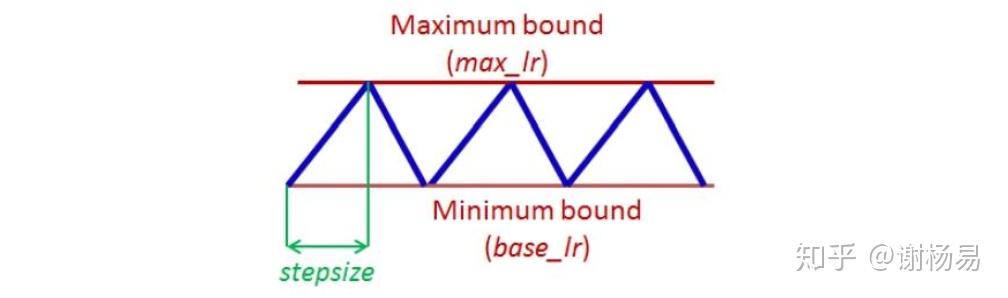
和Cyclical LR类似,但增大时为阶跃增大,如下
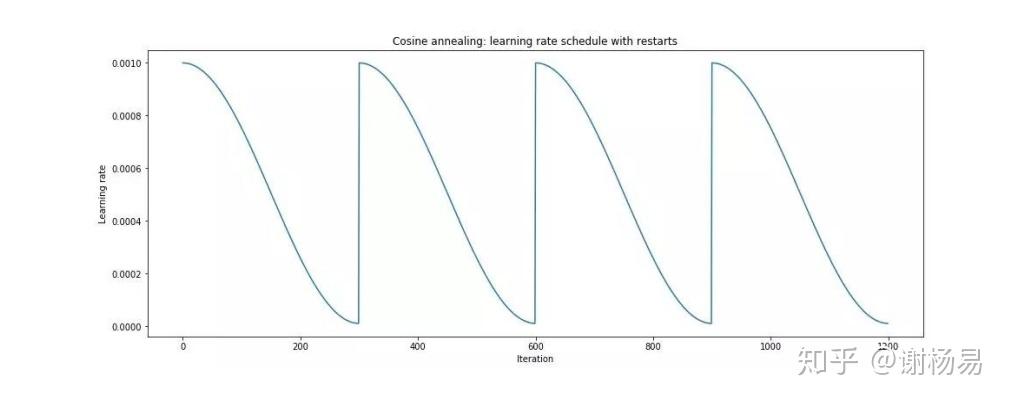
2020最新文章,
参数迭代n步后,再退回来一步。以新的起点重新开始迭代,这样可以增加收敛稳定性,防止跑飞。
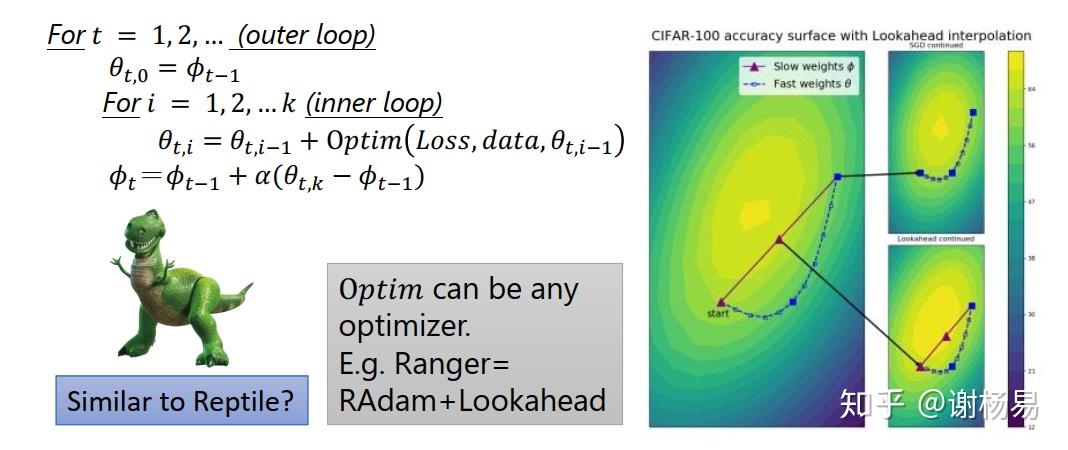
往future看几步,保证模型训练稳定

Adam的future版本


和加入正则类似,但不同的是它加入的是weight decay。Huging Face的预训练模型广泛应用了AdamW作为优化器,需要重点掌握。
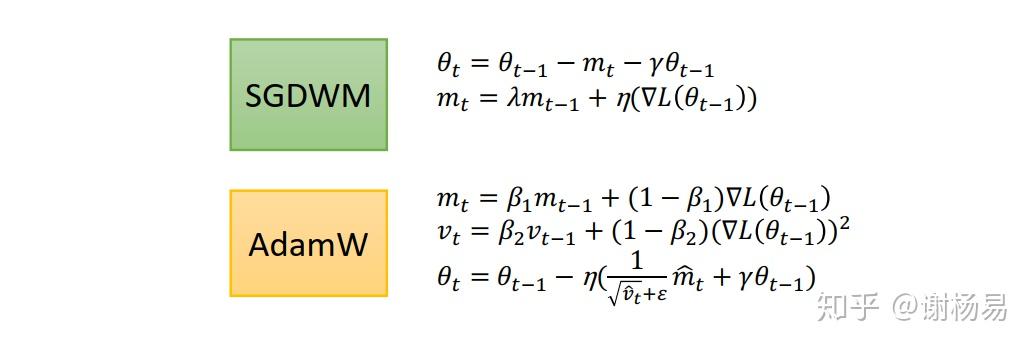
总结下来,SGDM和Adam两大阵营的各种优化后的optimizer如下
optimizer优化主要有三种方法







